Self-Adversarial Multi-scale Contrastive Learning for Semantic Segmentation of Thermal Facial Images
Thermal imaging offers unique advantages for physiological monitoring and affective computing, but segmenting thermal facial images remains a formidable challenge. Unlike RGB images with prominent visual features, thermal images represent temperature distributions that are subtle, dynamic, and easily disrupted by occlusions like glasses or hair. How do we train robust segmentation networks when most existing approaches are designed for RGB images and large-scale thermal datasets are scarce?
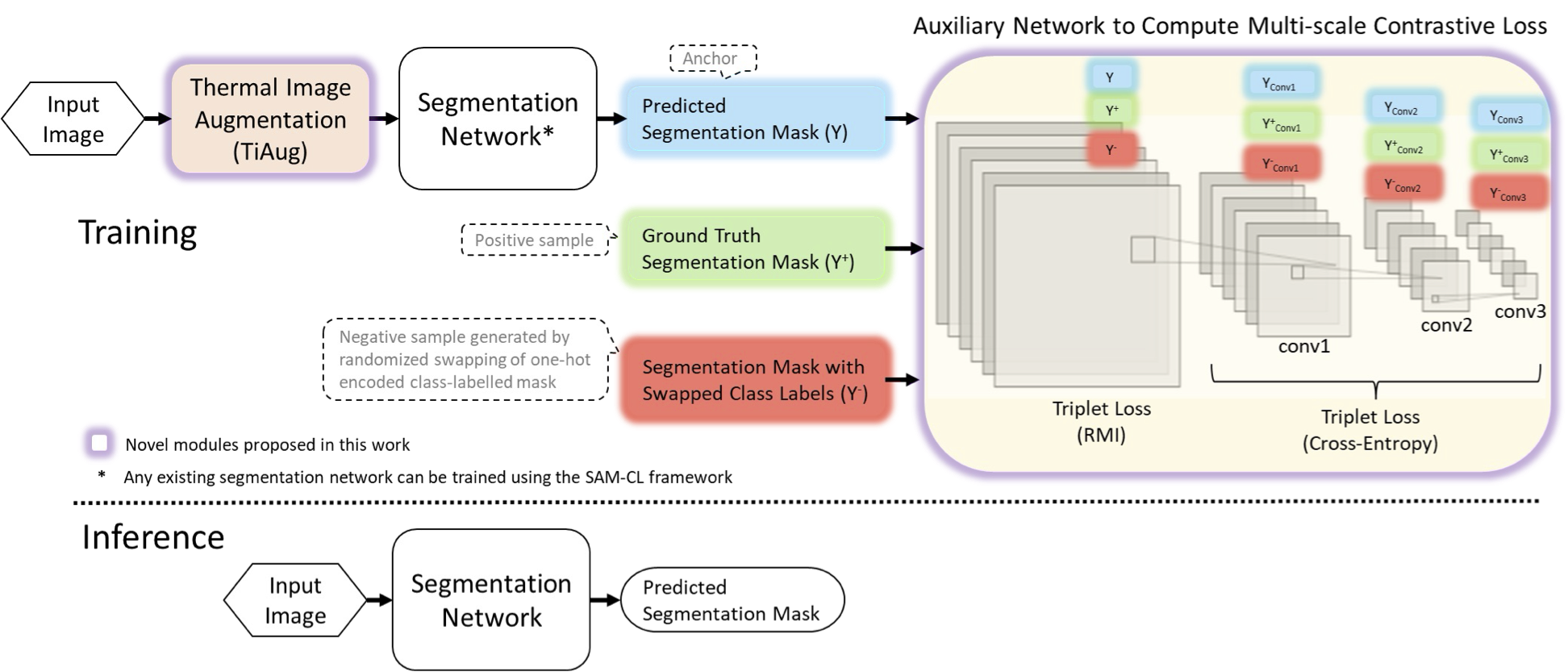
Figure 1: Overview of our SAM-CL framework showing how thermal image augmentation (TiAug) creates realistic unconstrained scenarios while the SAM-CL loss function learns robust representations through self-adversarial training.
The Challenge: When RGB Methods Fall Short
Traditional semantic segmentation networks excel on RGB images with rich visual features and abundant training data. However, thermal facial images present unique challenges:
- Subtle temperature variations across facial regions
- Dynamic physiological changes affecting temperature patterns
- Frequent occlusions from glasses, hair, and ambient objects
- Limited datasets acquired mostly in controlled laboratory settings
Existing data augmentation techniques designed for RGB images (brightness, contrast adjustments) don’t translate meaningfully to thermal images, where temperature represents physical properties rather than illumination conditions.
Our Solution: SAM-CL Framework
We introduce the Self-Adversarial Multi-scale Contrastive Learning (SAM-CL) framework, consisting of two key innovations:
1. Thermal Image Augmentation (TiAug) Module
TiAug transforms controlled thermal images into realistic unconstrained scenarios by:
- Synthesizing occluding objects with diverse thermal properties, shapes, and positions
- Adding calibrated thermal noise based on camera sensitivity (e.g. noise equivalent temperature difference (NETD))
- Creating realistic temperature distributions that break the bimodal histogram patterns, which are typical in controlled settings
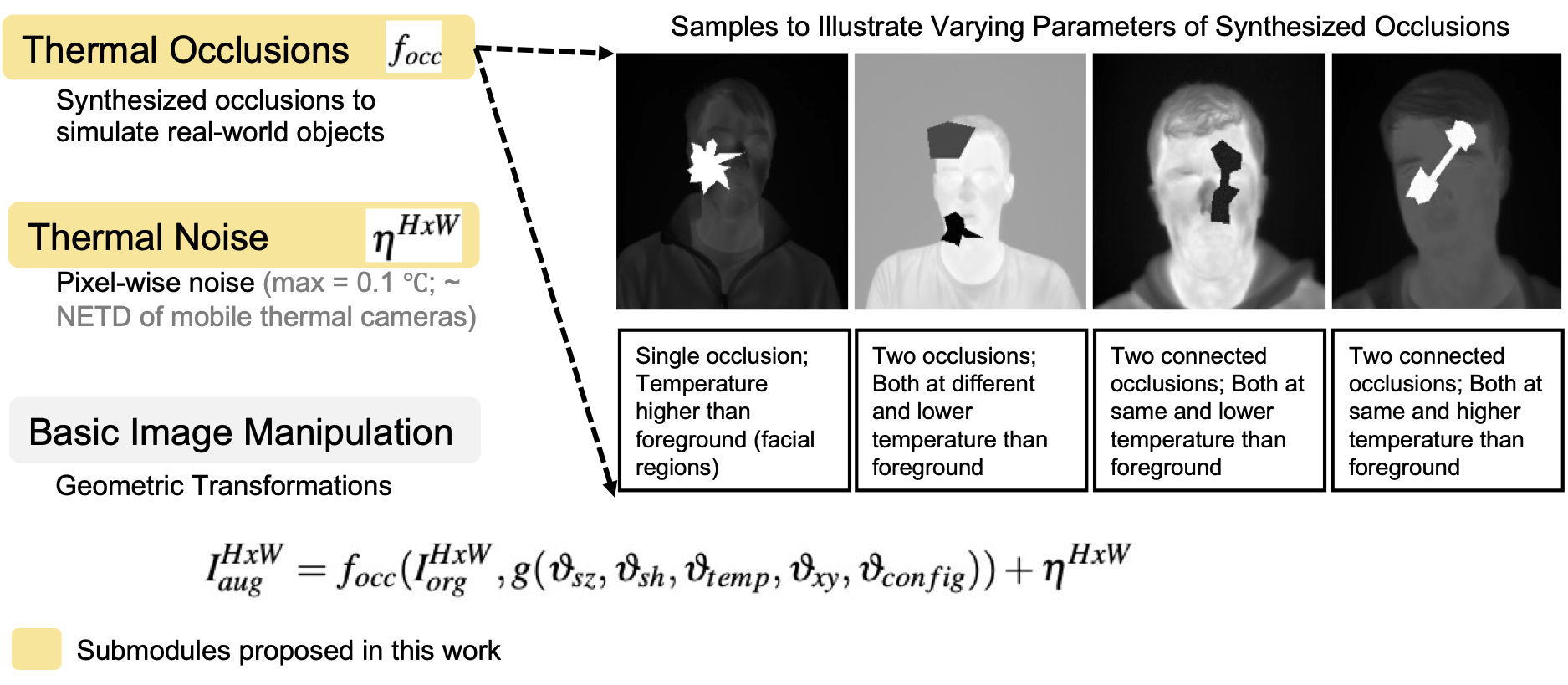
Figure 2: TiAug module generates realistic thermal scenarios with varying ambient conditions and occlusions, moving beyond simple geometric transformations.
The augmentation is mathematically formulated as:
\[I_{aug}^{HxW} = f_{occ}(I_{org}^{HxW}, g(\vartheta_{sz}, \vartheta_{sh}, \vartheta_{temp}, \vartheta_{xy}, \vartheta_{config})) + \eta^{HxW}\]where synthesized objects are characterized by size (\(\vartheta_{sz}\)), shape (\(\vartheta_{sh}\)), temperature (\(\vartheta_{temp}\)), position (\(\vartheta_{xy}\)), and configuration (\(\vartheta_{config}\)).
2. SAM-CL Loss Function
Rather than using pixel-level contrastive learning that becomes ineffective with limited datasets, we propose logit-level contrastive learning:
\[\mathscr{L}_{SAM-CL} = \mathscr{L}_{s0}(Y_{oh}, Y^{+}_{oh}, Y^{-}_{oh}) + \mathscr{L}_{s1}(Y_{Conv1}, Y^{+}_{Conv1}, Y^{-}_{Conv1}) + \mathscr{L}_{s2}(Y_{Conv2}, Y^{+}_{Conv2}, Y^{-}_{Conv2}) + \mathscr{L}_{s3}(Y_{Conv3}, Y^{+}_{Conv3}, Y^{-}_{Conv3})\]The key innovation is using class-swapped masks (\(Y^-_{oh}\)) as negative samples, enabling effective inter-class separation while preserving spatial structure. Multi-scale supervision through an auxiliary 4-layer network ensures robust feature learning across different resolution levels.
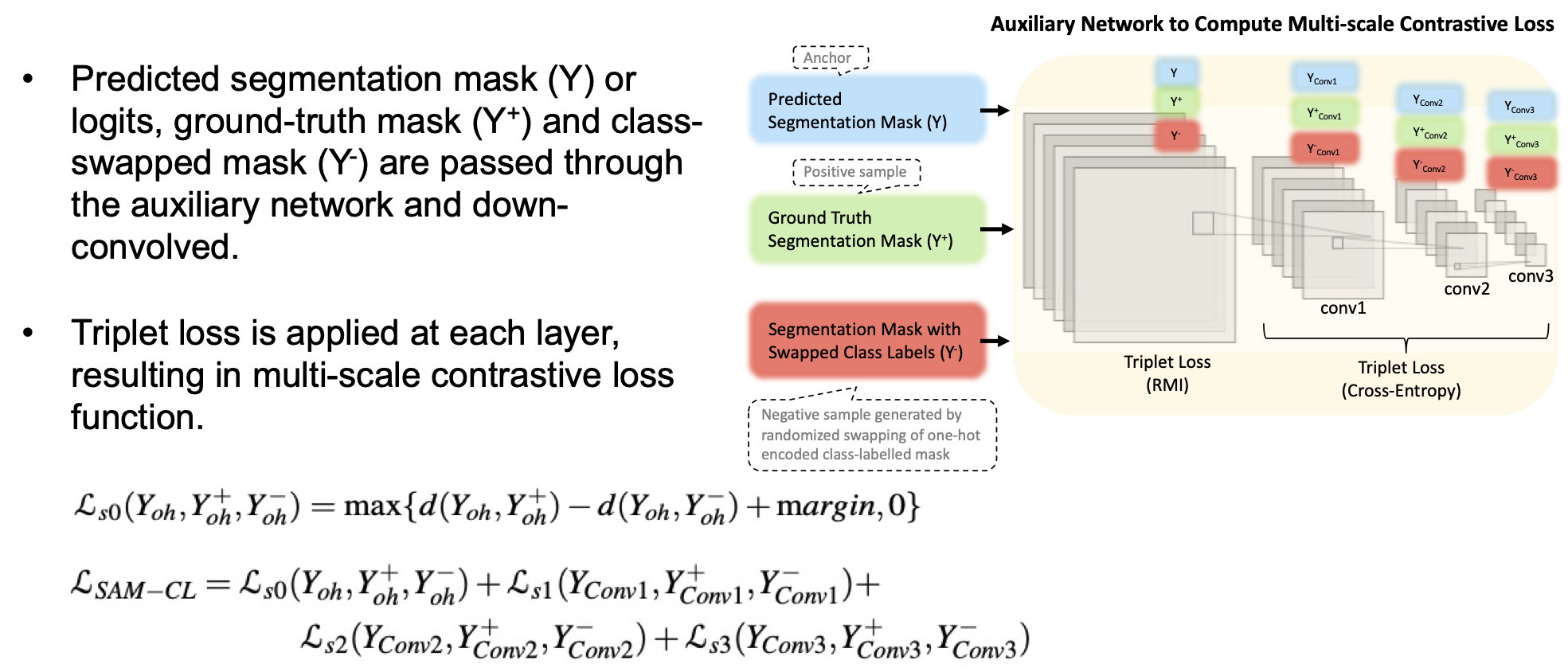
Figure 3: Proposed SAM-CL Loss Function.
Experimental Results
We evaluated SAM-CL across multiple state-of-the-art segmentation networks on the Thermal Face Database:
Table 1: Performance improvements with SAM-CL framework
| Network | Baseline (RMI) | SAM-CL | Improvement |
|---|---|---|---|
| U-Net | 81.36% | 82.11% | +0.76% |
| Attention U-Net | 81.39% | 82.85% | +1.35% |
| DeepLabV3 | 75.85% | 79.29% | +3.44% |
| HRNetV2 | 78.46% | 78.97% | +0.61% |
Qualitative Analysis: Real-World Robustness
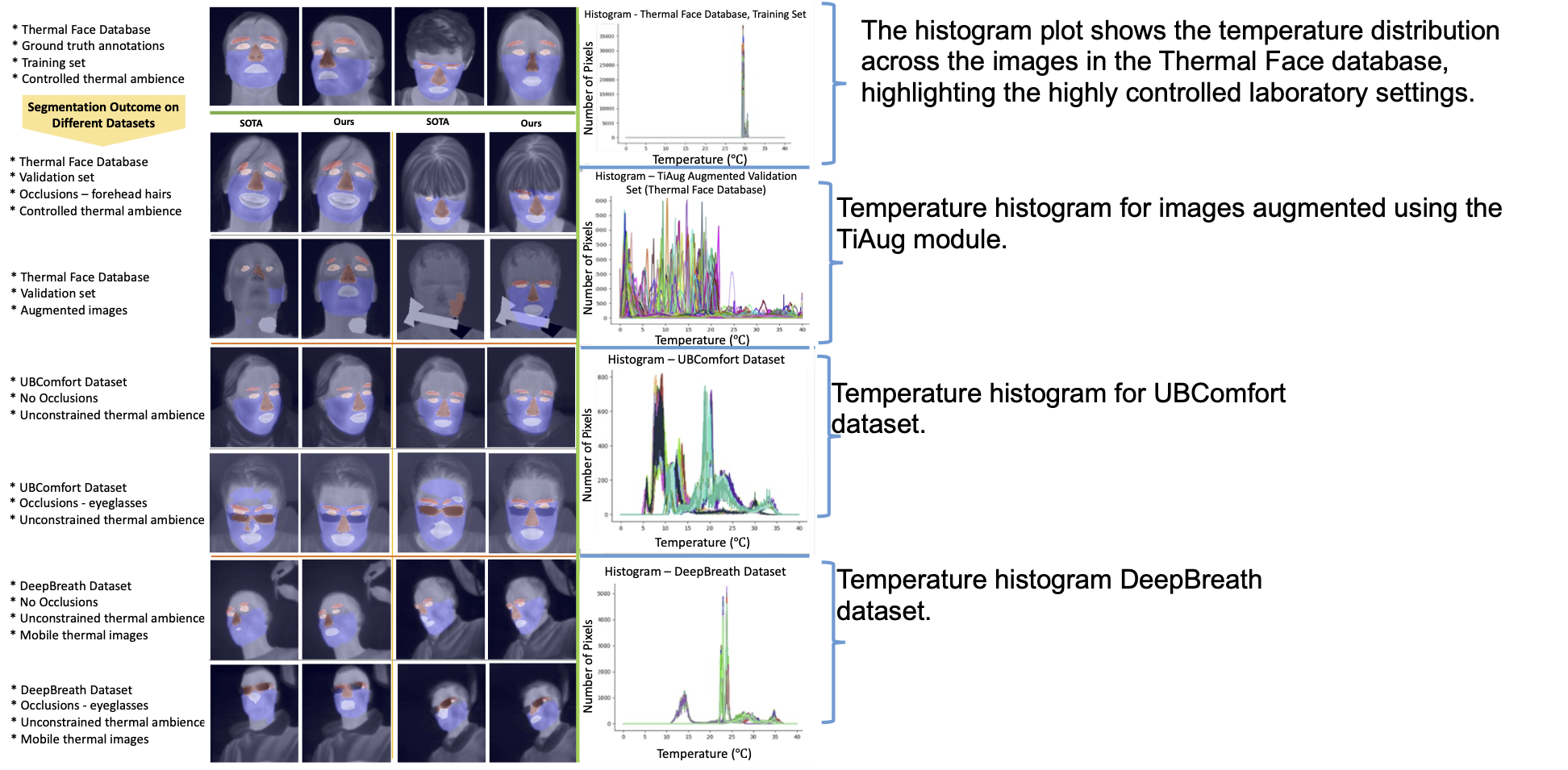
Figure 3: Qualitative comparison showing SAM-CL’s superior performance on unconstrained thermal images with occlusions and varying ambient conditions.
Testing on unconstrained datasets (UBComfort, DeepBreath) reveals SAM-CL’s remarkable generalization:
- Handles eyeglasses occlusions effectively despite never seeing them during training
- Adapts to different camera specifications (high-resolution vs mobile thermal cameras)
- Maintains performance across varying ambient thermal conditions
Demo

Key Insights and Broader Impact
Why This Approach Works
- Domain-Specific Design: TiAug successfully generates real-world variations, not just visual appearance
- Self-Adversarial Learning: Creates challenging scenarios without requiring real unconstrained data
- Multi-scale Supervision: Ensures robust features across different granularities
- Logit-Level Contrastive Learning: More effective than pixel-level approaches for limited datasets
Applications Beyond Thermal Imaging
The SAM-CL framework’s principles extend to any domain with:
- Limited training data
- Significant domain gaps between controlled and real-world conditions
- Need for robust feature learning across scales
Implementation and Reproducibility
Our framework is designed for easy integration:
# SAM-CL can be applied to any segmentation network
model = UNet() # or AttentionUNet, DeepLabV3, etc.
optimizer = SAM_CL_Optimizer(model, sam_cl_loss, tiaug_module)
# Training with SAM-CL
for batch in dataloader:
augmented_batch = tiaug_module(batch)
predictions = model(augmented_batch)
loss = sam_cl_loss(predictions, targets)
optimizer.step()
Looking Forward
This work opens exciting directions for robust computer vision in challenging domains:
- Medical imaging with limited annotated data
- Satellite imagery with varying atmospheric conditions
- Industrial inspection with changing environmental factors
The key insight is profound: when datasets are limited and domain gaps are large, task-specific augmentation paired with appropriate learning strategies can bridge the gap more effectively than simply scaling existing RGB-based approaches.
Source Code: Code is available for the research community to build upon this work.
Citation:
@inproceedings{Joshi_2022_BMVC,
author = {Jitesh N Joshi and Nadia Berthouze and Youngjun Cho},
title = {Self-adversarial Multi-scale Contrastive Learning for Semantic Segmentation of Thermal Facial Images},
booktitle = {33rd British Machine Vision Conference 2022, {BMVC} 2022, London, UK, November 21-24, 2022},
publisher = {BMVA Press},
year = {2022},
url = {https://bmvc2022.mpi-inf.mpg.de/0864.pdf}
}
This work was conducted at the Department of Computer Science, University College London, under the supervision of Prof. Youngjun Cho. Jitesh Joshi was fully supported with international studentship that was secured by Prof. Cho
For questions or collaborations, please contact: jitesh.joshi.20@ucl.ac.uk